Modelagem Preditiva para Problemas de Classificação
O objetivo deste post é apresentar alguns exemplos de Modelagem Preditiva para Problemas de Classificação, que fazem uso de sistemas de aprendizagem de máquina supervisionados.
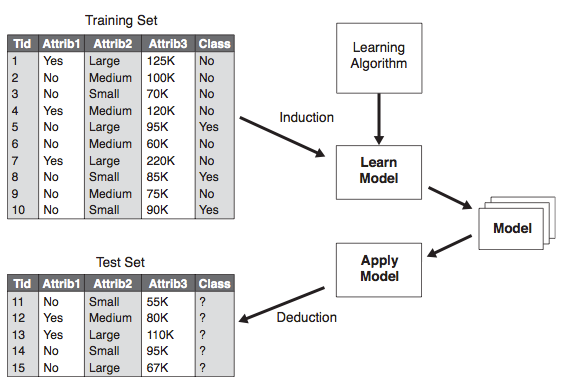
Um sistema de aprendizagem de máquina supervisionado é um programa capaz de induzir uma descrição de um conceito a partir de um conjunto de exemplos previamente conhecidos e rotulados com suas respectivas classes. Essa descrição é uma generalização dos exemplos fornecidos ao sistema e é, normalmente, referenciada na literatura como hipótese. O objetivo principal de uma hipótese é, dado um novo exemplo cuja classe é desconhecida, predizer sua classe.
Abordagem genérica para construção de classificadores [1]
Exemplo de uso do Algoritmo Random Forest
Neste exemplo foi utlizado um dataset com 150 exemplos e 3 classes (tipos) da planta iris. Trata-se de um dataset clássico na área de data mining e machine learning. Para criar um modelo que consegue separar as três classes foi utilizado o algoritmo Random Forest. O algoritmo Random Forest é um tipo de ensemble learning, método que gera muitos classificadores e agrega o seu resultado. No caso do Random Forest, ele gera múltiplas árvores de decisão que depois são utilizadas na classificação de novos objetos. O script utilizado neste exemplo pode ser acessado aqui. Neste script, o primeiro modelo testado é:
forestIris <- randomForest(
Species ~ Petal.Width + Petal.Length, data = iris)
Onde o dataset utilizado são todos os 150 exemplos. Este primeiro modelo gera um erro estimado de 4%. Outros três modelos são gerados (com um erro também próximo de 4%) e depois combinados em um único modelo. O modelo combinado tem um erro de 1.3%, como mostra a matriz de confusão abaixo:
| setosa | versicolor | virginica | |
| setosa | 50 | 0 | 0 |
| versicolor | 0 | 49 | 1 |
| virginica | 0 | 1 | 49 |
Por fim é gerado um dataset artificial com 1.000 exemplos e com uma distribuição similar ao dataset original apenas para ilustrar como o algoritmo Random Forest consegue separadas dados que não são separáveis linearmente.
Exemplo de uso de algoritmos indutores de árvore de decisão
O objetivo deste exemplo é mostrar a utilização de um algoritmo indutor de árvore de decisão na construção de classificadores para o problema da iris plant (o mesmo dataset do exemplo anterior). O script utilizado neste exemplo pode ser acessado aqui. Neste script, a primeira etapa consiste em dividir aleatoriamente o dataset em uma parte para o treinamento (70% dos exemplos do dataset) e outra parte para o teste do modelo (30% dos exemplos do dataset).
Para a criação do classificador são utilizados dois algoritmos: (i) ctree do pacote party, e; (ii) J48 do pacote RWeka. Ambos os modelos são testados no conjunto de teste. O modelo gerado a partir do algoritmo ctree tem uma acurácia de 95% e o modelo gerado a partir do J48 tem uma acurácia de 98%. Além do método para teste de modelos que divide o conjunto original em dois, também foi aplicado o método de validação chamado cross-validation. O modelo gerado pelo algoritmo ctree obteve um erro médio de 6.53% e o modelo gerado pelo J48 obteve um erro médio de 5.13%.
Da mesma forma que no exemplo anterior foi gerado um dataset sintético para ilustrar como o algoritmo Random Forest consegue separar dados que não são separáveis linearmente, neste exemplo também fez-se o mesmo para mostrar como algoritmos de indutores de árvore de decisão geram modelos que apenas separam dados de forma linear.
Classificação de Spam usando o algoritmo J48 e o algoritmo Random Forest
O objetivo destes dois exemplos [J48,RandomForest] é mostrar a utilização dos algoritmos J48 e Random Forest na construção de classificadores de Spam. Construir classificadores de email (Spam) é um típico problema de Text Mining (Mineração de Textos). No entanto, como este dataset já está pré-processado, este exemplo não chega a discutir aspectos relacionados a Mineração de Textos.
O dataset analisado tem 57 atributos e 4.601 exemplos. Para a avaliação dos modelos, o dataset foi divido aleatoriamente em um conjunto para treinamento (70% dos exemplos) e um conjunto para teste (30% dos exemplos). Foram criados dois classificadores: (i) uma árvore de decisão gerada pelo J48, e; (ii) uma floresta de árvores de decisão gerada pelo algoritmo Random Forest. A acurácia obtida pela árvore de decisão foi de 91.99% e a acurácia obtida pela floresta de árvores de decisão foi de 94.93%.
O modelo resultante do algoritmo Random Forest possui 500 árvores. No entanto, segundo o gráfico de erro estimado por número de árvores existente no modelo, seria possível utilizar um modelo mais simples, com 200 árvores, e com a mesma acurácia.
Outro resultado da análise feita durante a construção do modelo foi a constatação da importância de determinados atributos. Por exemplo, a quantidade de vezes que um ponto de exclamação é utilizado, a quantidade de vezes que o caracter de dólar ($) é utilizado, a quantidade de vezes que a palavra free e remove são utilizadas são fortes indicadores para determinar se um email é Spam ou não.
Reconhecimento de atividades humanas
O objetivo deste trabalho é construir um classificador de atividades realizadas por pessoas a partir de informações coletadas de quatro acelerômetros localizados em lugares diferentes do corpo da pessoa. O dataset utilizado neste trabalho foi obtido aqui. Este dataset possui 165.633 exemplos e 19 atributos. Depois da aquisição dos dados, os mesmos foram dividos aleatoriamente em conjunto de treinamento (60%) e conjunto de teste (40%). Utilizando o conjunto de treinamento foi feito uma análise descritiva dos dados e a criação de dois modelos: um que utiliza todos os dados dos quatros acelerômetros e outro que utiliza apenas os dados coletados pelo acelerômetro localizado na cintura.
O primeiro modelo teve um erro estimado de apenas 0.54%, enquanto que o modelo que utiliza apenas o acelerômetro localizado na cintura teve um erro estimado de 17.12%. Ao aplicar o modelo completo no conjunto de teste a acurácia medida foi 99.4%. Mais informações sobre este trabalho podem ser obtidas aqui.
Considerações sobre os exemplos apresentados
TBD